
Free Report
Veeam is a Four-Time Leader and Outperformer
See why Veeam’s Kubernetes data protection solution outranks competitors
KASTEN K10
#1 Kubernetes
Data Protection
- Security everywhere
- Reliable backup and fast recovery
- Application freedom

Experience the Kasten K10 Difference
Kubernetes Native
Kasten K10 is purpose-built for Kubernetes and is constructed using cloud native architectural principles. It follows a desired state model, providing declarative control.
Security Everywhere
Achieve comprehensive end-to-end security via enterprise-grade encryption, Identity Access Management (IAM), Role Based Access Control (RBAC), OpenID Connect (OIDC) and more.
Easy to Use
Kasten K10 offers quick deployment and provides a user-friendly, start-of-the-art management interface or a cloud native API. It also has the versatility to accommodate complex applications easily.
Rich Ecosystem Support
Leverage extensive support for ecosystem components across the entire application stack and choose the tools or infrastructure that work best for you.
Kubernetes Data Protection Use Cases




Easy, Scalable Security for Your Kubernetes Data
Kubernetes has become the fastest-growing infrastructure platform and is on track to be the next enterprise platform of choice.
While it provides high availability and scalability for application services, these benefits do not extend to your data, which makes Kubernetes application data protection critical.
Kasten K10 provides enterprise operation teams with an easy-to-use, scalable, and secure system for backup & restore, disaster recovery (DR) and application mobility. With Veeam, teams achieve radical resilience against ransomware attacks.

Explore the Capabilities of Kasten K10
Security Everywhere
Don’t be a victim of cyberattacks – treat data protection as a Day 0 operation.
Ransomware Protection
Ensure your data is safeguarded with backup immutability and always-on encryption.
Kubernetes Native RBAC
Deliver secure self-service across teams and personas.
Security Ecosystem
Integrate with industry-leading SIEM, Policy-as-Code, and KMS tools.
Reliable Backup and Fast Recovery
Protect your cloud native applications with a 100% Kubernetes native solution.
Simple Recovery
Recover working applications in-place, cloning, or recovering to other clusters.
Intelligent Policies
Support enterprise-scale operations with built-in automation.
Application Consistency
Customize your application integration for every Kubernetes workload.
Application Freedom
Protect all your data anywhere, any way, with application mobility and zero lock-in.
Application Mobility
Enable hybrid or multi-cloud across different distributions, clouds, and infrastructure.
VMs on K8s & Databases
Accelerate application transformation by supporting diverse workloads.
Freedom of Choice
Explore what works best for you with support from the broadest ecosystem of supported distributions, infrastructure, and applications.
Kasten K10 V6.5
Unlock cloud native security and enterprise-scale Kubernetes innovations.
- Ransomware protection advances
- Hardened federal container registry
- Large-scale multi-cluster operations & multi-app restores
Kubernetes Data Protection Made Easy
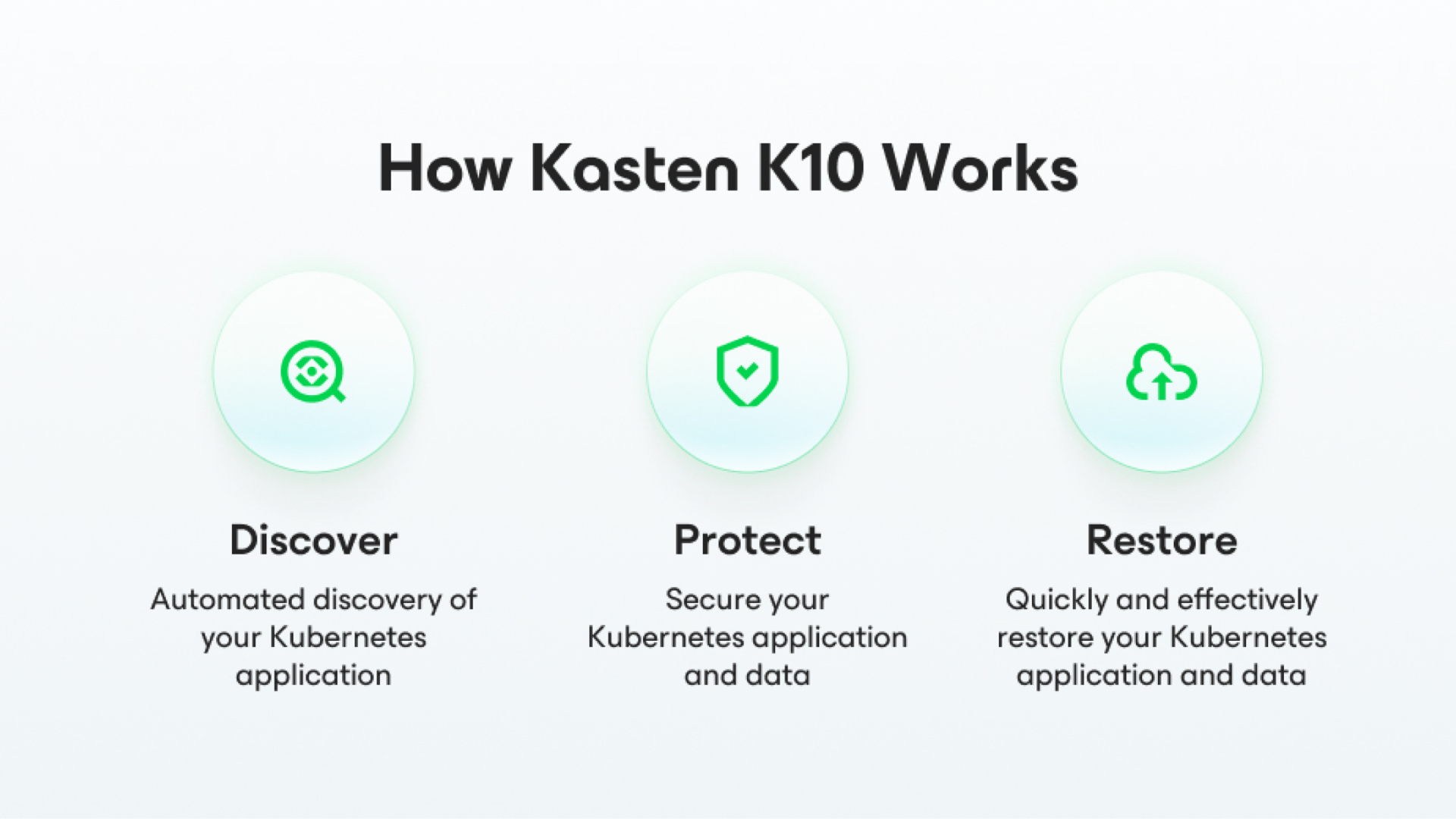
Protect Your Kubernetes Applications in Three Simple Steps
Kasten K10 is easy-to-use, here is how it works in three simple steps:
- Automatically discover your Kubernetes applications and all dependencies
- Create a copy of your Kubernetes applications and data
- Restore your entire application and data with a single click
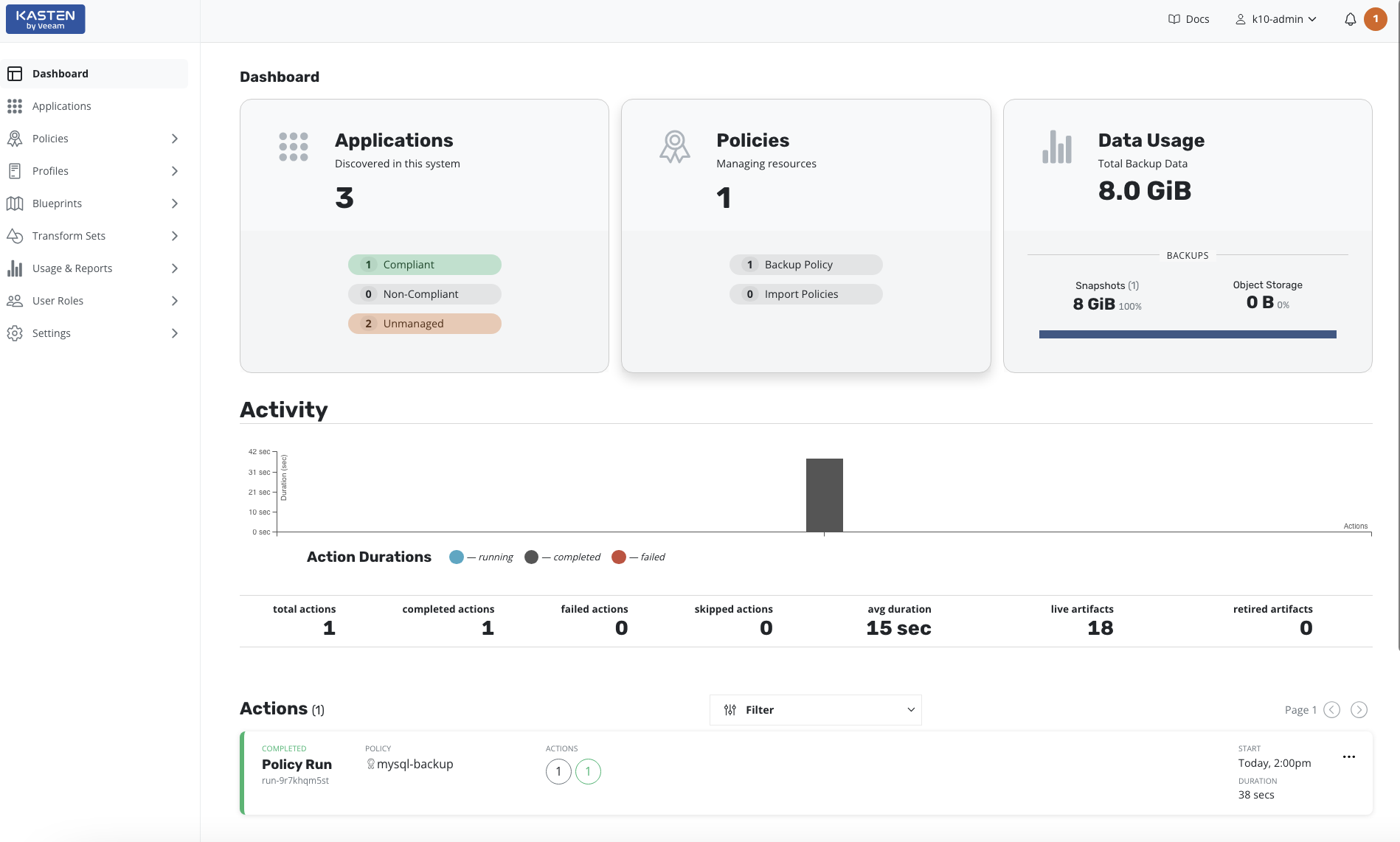
Automated Discovery of Your Kubernetes Applications
Leverage the power of automated Kubernetes application discovery and dependency inventories, including resource definitions, configurations, and underlying data. Plus, Kasten K10 integrates seamlessly with relational and NoSQL databases and all major Kubernetes distributions.
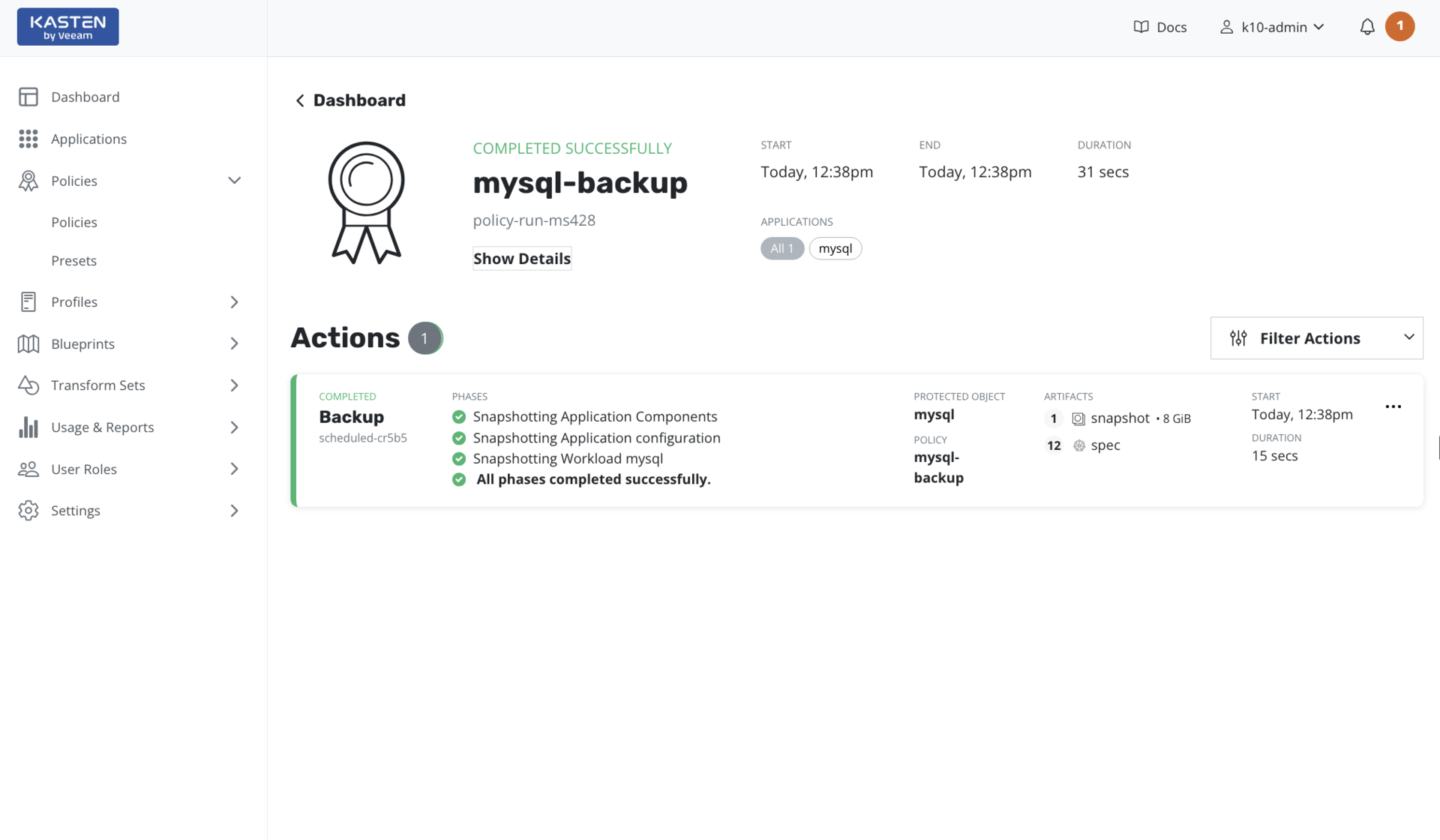
Secure Your Kubernetes Application and Data
Create a copy of containers and specified data, and automatically updates the backup at a rate that’s designated by you. Ensures comprehensive protection across multiple clusters and clouds, and automated policies enable you to meet your backup SLAs.
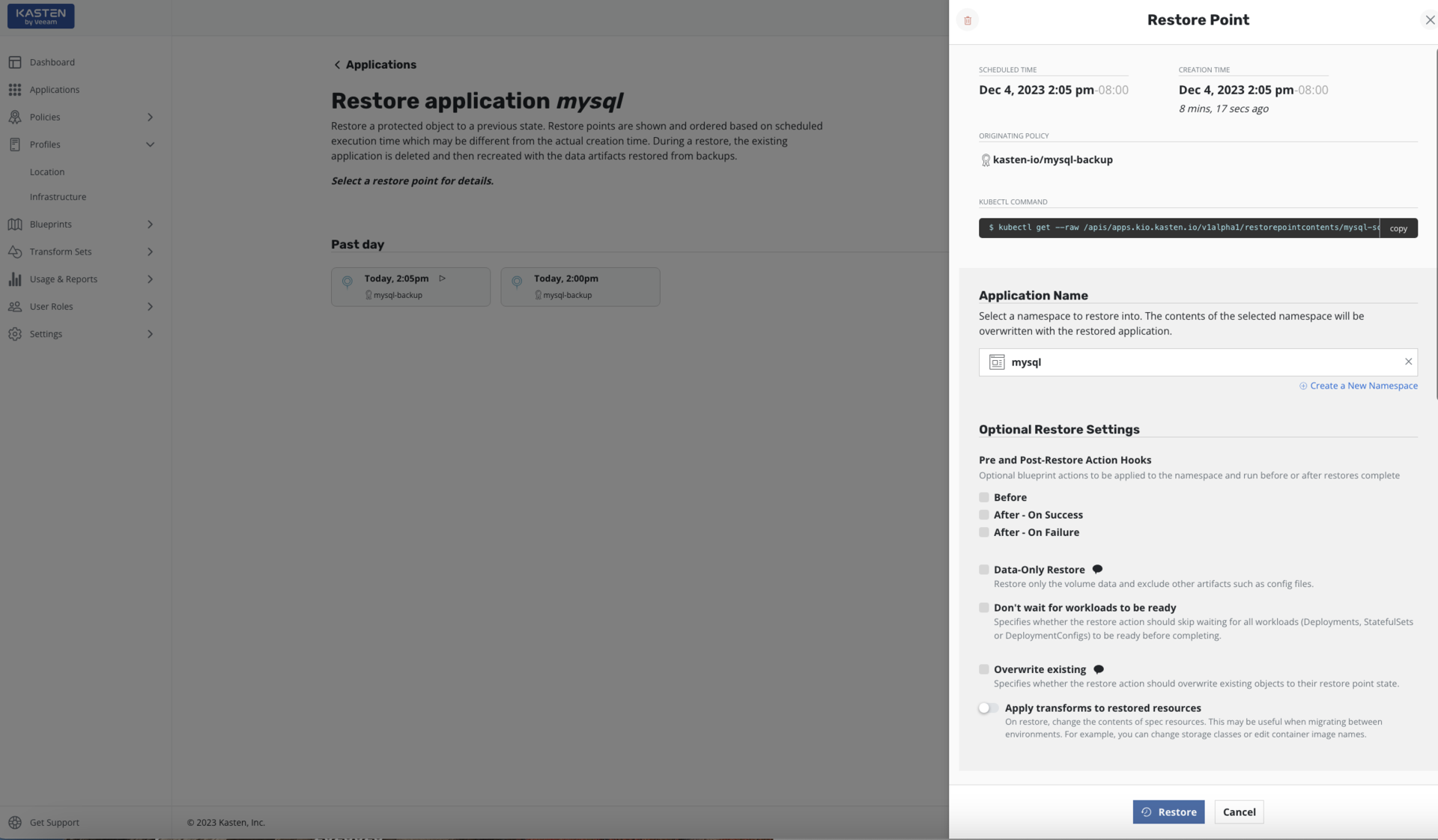
Quickly and Effectively Restore Your Kubernetes Application and Data Anywhere
Restore the entire application and data across clusters, regions, and clouds. Recover from user errors, infrastructure failure, disasters or malicious attacks. Leverage blueprints to properly orchestrate the restore of your application and data.
Cloud Native Ecosystem
Data Protection and Management Solutions
Kubernetes Data Protection Platform
Data
Services
 Amazon RDS
Amazon RDS Cassandra
Cassandra MongoDB
MongoDB SQL Server
SQL Server PostgreSQL
PostgreSQL MySQL
MySQL K8ssandra
K8ssandra Elasticsearch
Elasticsearch Kanister
Kanister Kafka
Kafka EDB
EDB
Kubernetes
Distributions
 Amazon EKS
Amazon EKS EKS-Anywhere
EKS-Anywhere AKS
AKS GKE
GKE Digital Ocean
Digital Ocean HPE Ezmeral
HPE Ezmeral Kubernetes
Kubernetes K3S
K3S NKE
NKE Mirantis
Mirantis OKE
OKE Openshift
Openshift SUSE Rancher
SUSE Rancher VMware Tanzu
VMware Tanzu
Storage
Infrastructure
 Amazon EBS
Amazon EBS ADS
ADS Amazon S3
Amazon S3 Ceph
Ceph CSI
CSI Cisco
Cisco GCS
GCS Dell EMC
Dell EMC- HPE
 Infinidat
Infinidat MinIO
MinIO Hitachi
Hitachi OCI
OCI Lenovo
Lenovo Zadara
Zadara Net App
Net App Pure Storage
Pure Storage
Security
Services
 Kyverno
Kyverno OPA
OPA Red Hat
Red Hat Vault
Vault AWS
AWS

Buying Kasten K10 for Kubernetes
Kasten K10 pricing is simple, it is node-based.
You can try Kasten K10 free using the Free Kasten K10 version or the Enterprise Trial.
The full Enterprise Edition is available through multiple procurement channels: Direct, partner or marketplace (e.g., Red Hat, AWS, SUSE).
- One/three/five-year subscription
- 24.7.365 support
- No nodes limit
Customers Protected by Veeam











Stay Updated With the Latest Kubernetes Insights and Trends

Veeam is a Four-Time Leader and Outperformer
Kubernetes applications require a Kubernetes native approach and Veeam’s Kubernetes data protection solution outranks competitors.
Open Source vs Enterprise Data Protection
Explore the difference in features, capabilities, and functionality between the two industry leading Kubernetes data protection tools.
5 Kubernetes Backup Best Practices
Kubernetes has emerged as the de-facto container orchestration platform. Learn how to address its unique data management needs.
Kubernetes Success Stories
Discover how businesses like yours use Kasten K10 to protect Kubernetes workloads, reduce risk, improve compliance, and more!
FAQs
What is Kasten K10?
What storage does Kasten K10 require?
Which data services does Kasten K10 support?
Which Kubernetes distributions does Kasten K10 support?
How difficult is it to install Kasten K10?
Which interfaces does Kasten K10 come with?
What security does Kasten K10 provide?
How does Kasten K10’s Automatic Application Discovery work?
Does Kasten K10 support multi-cluster management?
Radical Resilience Starts Here
hybrid cloud and the confidence you need for long-term success.